About Me
I have background in mathematics and deep roots in engineering and I’ve been involved in artificial intelligence long before it became a buzzword. My drive has always been the same: dig beneath the surface, understand how things really work, and never settle for black-box thinking. A curious mind has led me through many corners of the digital world. While I use modern tools to increase effectiveness, I don’t rely on them blindly. Call me old-school in this era of conversational programming—but just like no building stands without an understanding of statics, no software system stands without grasping its foundations. Whether through hands-on tinkering or meticulous reading of documentation, I first make sure I understand. Then I build.
I build with special attention to have each part well composed into a project. I'm not a fan of disposable things, hence I like to approach each project in a plain manner, keeping an eye on potential long-term complexity. Well documented and tested code is a must. A simple and stable project is an aspiration.
What Sets Me Apart My seniority is grounded in: - Studying mathematics, computer science, and cognitive science - Years of experience across startups, corporations, and academia - Wearing many hats: full-stack developer, backend engineer, data scientist, data engineer, ML practitioner - Working across domains: cloud engineering, infrastructure, databases, statistical modeling, networking, software design Whatever I work on, I bring in knowledge from multiple disciplines—and I like to get my hands dirty.
Check out the details.Data Engineering
Building scalable, secure, efficient, low-cost data pipelines, architecture, and infrastructure management. Scroll down for my de quirks.
Architecture
Designing and maintaining efficient, scalable data architectures for large systems.
Containers
"Works on your machine"? Good for you. Now let's wrap, isolate it. Let's containerize it. Containers let us package software in a portable, scalable and reproducible way.
We only need to configure environment once, which saves time, nerves, and future headaches for yourself and anybody, that will work with your code.
Furthermore, containerized applications are isolated from the host system, which means they will run consistently across different environments, regardless of OS or hardware. This isolation ensures that dependencies, configurations, and runtime behavior remain predictable.
From a cloud infrastructure perspective, containers are in the heart of scalable, resilient system design. They can be orchestrated with tools like Kubernetes or AWS ECS to automatically scale based on demand, roll out updates without downtime and recover from failures.
Use case
Typical use case looks like: machine learning model is trained locally but needs to run in production with a scheduled retraining pipeline, batch inference, and real-time API. By containerizing it:
- You can test it locally with the same setup it will have in production.
- Deploy it as a microservice in a Kubernetes cluster on AWS.
- Attach it to a CI/CD pipeline for versioned deployments.
- reproducibility, rollback and conceptual separation (e.g. model training, inference, preprocessing run in separate containers).
Real-world example
In one project, I developed a data ingestion pipeline that pulled metrics from external APIs, transformed them, and stored the results in a cloud warehouse. By containerizing the components—API collector, transformer, database writer - we could deploy them as separate, independently scalable services. When the API load spiked, only the collector needed to scale up. And when the schema changed, we swapped out the transformer container with a new version, without touching the rest of the system.
Containerization doesn’t just make software portable - it makes infrastructure modular, scalable, and maintainable.
CI/CD
I like to automate everything in a way, that no effort is spent on development process itself and we can focus on what really matters. A proper, fully automated ci cd is a non-negotiable. A little showcase on github repo, with which I wanted to excite our team.
Infrastructure as Code
I once accidentally deleted a server during a hobby project. Months of work was wiped in a second. I remained cool as a cucumber. Within an hour, everything was back up: configs restored, databases seeded, services running like nothing ever happened. That experience sealed it for me: manually configuring servers is a liability.
My rule is simple: Thou shalt not touch a server with a mouse.IaC allows you to define your infrastructure—servers, networks, databases, load balancers, permissions... as declarative code. In practice it means the infrastructure is versioned, repeatable, testable, and reviewable.
Why it matters
- Reliability: Every environment is created from the same source of truth. No surprises, no manual tweaks.
- Speed: Bring up a new environment with one command. Provision a replica system in minutes.
- Audit & History: Want to know what changed last week? Or roll back to a working config? Just check your Git history.
- Collaboration: Infrastructure becomes a team activity. No more tribal knowledge stuck in terminal history or sticky notes.
Machine Learning
Deep dive into two projects I've done 2015 and 2018, respectively.
Reinforcement Learning
Behavioural science draws conclusions through the results of behavioural observations. In particular, it is trying to predict animal's internal states and processes based on indirect measurements and/or observations of the animal's behaviour. Cognitive science endeavors for years on revealing the content of the black box, as revealing the inner workings between input (stimuli) and output (response).
The aim of our project was an implementation of a framework with models that imitate animal's behaviour and to evaluate, which model fits best animal's behaviour. This allows us to reveal the inner workings on the basis of very simple observations. The evaluation framework is composed of two components: models and evaluation. The framework's input are data, that describe a simple animal's behaviour in a form of trajectories in space and time. Models are fitted to the data, which in term generates new trajectories with fitted parameters. A newly generated trajectory is compared with an original one and an evaluation method returns an information about which model fits better to the inputs. The selected model reveals an underlying inner structure.
Implementation
The framework was implemented on a basis of a pilot study [1]. Furthermore, for complex definition of an agent we draw inspiration from a strategy game [2].
The implememtation was carried out using two complementary libraries: OpenAi Gym [3] and rllab [4]. Gym provided us a standardized interface and benchmark environment, while rllab offered a flixible framework for developing and evaluating reinforcement learning algorithms. A combination of the toolkits yielded a following structure:
- environment
- agent
- evaluation
- reconstruction
Simulation framework
To implement simulation we use Markov Decision Process theory, which represents agent's internal states, beliefs and desires, its planning process and its interaction with the environment and encodes environment's limits.
def simulate (self,
n=1000,
x0=0,
y0=0,
x_vel0=0,
y_vel0=0,
angular_vel0=0,
heading0=0,
**_):
# The first state will be the original state
states = [pd.Series(dict(x=x0,
y=y0,
x_vel=x_vel0,
y_vel=y_vel0,
angular_vel=angular_vel0,
heading=heading0))]
# Run n steps
for _ in range(n):
states.append(self.next(**states[-1]))
# Return a dataframe with all the observations indexed by time [sec]
return pd.DataFrame(states, index=np.arange(n + 1) * self.dt)
To train an agent to imitate animals behaviour we used reinforcement learning. RL is a computational approach, that addresses the problem of how agents should learn to take actions to maximize cumulative reward through interactions with an environment.
def fit(self, model_type):
"""
Initializes TRPO (trust region policy optimization) algorithm and uses
it to train the model, determined with model_type. After the training,
the iteration that collected the best cumulative reward. A policy of
the iteration is saved to a blobal variable and the associated
trajectory saved to pickle file.
Parameters
----------
model_type : string
name of a model, that is to be fit to the ground truth trajectories.
Valid types are:
- 'object_approaching_model'
- 'object_avoidance_model'
- 'reflexive_goal_oriented_model'
Returns
-------
float
cumulative reward, collected at the best iteration
"""
episode_provider = Episodes(
ground_truth_model=self.ground_truth_model,
fitting_model=fitting_model,
initial_observations=self.train_initial_observations,
snapshot_dir=self.directory,
train=True
)
env = TrajectoryImitationEnv(
episode_provider=episode_provider,
one_step_forecast=False
)
self.norm_env = normalize(env, normalize_reward=True)
# creates an agent
policy = GaussianMLPPolicy(
env_spec=self.norm_env.spec,
hidden_sizes=self.network_setup
)
baseline = LinearFeatureBaseline(env_spec=self.norm_env.spec)
self.algo = TRPO(
env=self.norm_env,
policy=policy,
baseline=baseline,
n_itr=NUMBER_OF_ITERATIONS,
store_paths=True,
discount=self.discount_factor,
n_samples=int(round(self.number_of_data * 0.66)),
batch_size=int(round(self.number_of_data * 0.66))
* self.max_path_length,
max_path_length=self.max_path_length
)
self.algo.train()
iteration_data_dict = joblib.load(op.join(
self.model_directory,
('itr_%s.pkl' % (NUMBER_OF_ITERATIONS - 1))
))
cumulative_reward = self.get_cumulative_reward(iteration_data_dict)
self.policy = iteration_data_dict['policy']
[self.log_reconstructed_trajectory(path, index)
for index, path in enumerate(iteration_data_dict['paths'])]
return cumulative_reward
Models
Each model stands for every hypothesis. It models animal's behaviour and as such should be distinguished from an ML model. A model describes a trajectory in terms of differential equations using x, y positions, x, y velocities, angle, angular velocity and position of an object on agent's retina at each time point.
Three different models were implemented. A model that describes an animal approaching a goal, an animal that is avoiding an obstacle and reflexive & goal oriented model as a combination of first two.
def next(self,
x,
y,
x_vel,
y_vel,
heading,
angular_vel,
**_):
"""
Method generates a next observation, based on given values, a previous
observation. For a calculation is using semi differential equations.
An angle between an agent heading and an object's direction dictates
the torque, which is multiplied by a scalar value, called gain.
Parameters
----------
x : float
x position of previous observation [m]
y : float
y position of previous observation [m]
x_vel : float
velocity along x axis of previous observation [m/s]
y_vel : float
velocity along y axis of previous observation [m/s]
heading : float
angle in which an agent is moving of prev observation [rad]
angular_vel : float
angular velocity of previous observation [rad/s]
Returns
-------
pd.Series
the calculated next observation
"""
# --- Avoid selfishness
dt = self.dt
mass = self.mass
object_x, object_y = self.object_location
gain = self.gain
rot_inertia = self.rot_inertia
rot_damping = self.rot_damping
force_forward = self.force_forward
air_drag = self.air_drag
# force_lateral = self.force_lateral
# Rotational force due to attraction/repulsion towards object
agent_object_angle = math.atan2(object_y - y, object_x - x)
position_retina = wrap_pi_pi(agent_object_angle - heading)
torque = gain * position_retina
angular_velocity_new = angular_vel + dt / rot_inertia
* (- rot_damping * angular_vel + torque)
heading_new = heading + angular_vel * dt
# Velocities
x_vel_new = x_vel + dt / mass
* (- air_drag * x_vel + force_forward
* math.cos(heading))
y_vel_new = y_vel + dt / mass
* (- air_drag * y_vel + force_forward
* math.sin(heading))
# Positions
x_new = x + x_vel * dt
y_new = y + y_vel * dt
# Result dictionary
new_state = {
'x': x_new,
'y': y_new,
'x_vel': x_vel_new,
'y_vel': y_vel_new,
'heading': heading_new,
'angular_vel': angular_velocity_new,
}
return pd.Series(new_state)
Evaluation
Training is guided through cumulative reward, which is a good metric to evaluate models.
LSTM Autoencoder Project
Carsharing companies encounter plenty of unreported damages on cars, which ends up being quite costly. The idea of the project was to implement a system that would detect damages in real time using simple vibration sensors. To determine whether a signal means that actual damage occured or a driver was simply driving on a gravel we used a machine learning algorithm.
Implementation
Each system gets calibrated for every type of a car. During calibration phase we collected signals and converted them into audio files. The data got preprocess and fit to a model. In production phase the data get stored in a cloud where a pretrained model is used for classification.
LSTM Autoencoder
Autoencoder consist of two parts: an encoder and a decoder. Once fit the encoder compresses the data, whereas the decoder reconstructs an original signal. The general idea of autoencoder is that the model is trained only on non-anomalous data, therefore a compression and a reconstruction of an original signal of anomalous data will result in bigger reconstruction error.
An example of a model implementation:
@property
def model(self):
inp_e = Input((20, 800)) # don't define the batch size
out_e = LSTM(units=80, return_sequences=False)(inp_e)
encoder = Model(inp_e, out_e)
inp_d = Input((80,))
out_d = Reshape((20, 4))(inp_d) # 20 steps of 4 elements
out_d1 = LSTM(800, return_sequences=True)(out_d)
decoder = Model(inp_d, out_d1)
model = Model(encoder.inputs, decoder(encoder(encoder.inputs)))
return model
Results
Next figure demonstrates a reconstruction error for anomalous and non-anomalous data. A figure demonstrates that a model was trained sufficiently well and that a threshold value could be set properly to separate classes based on reconstruction error:
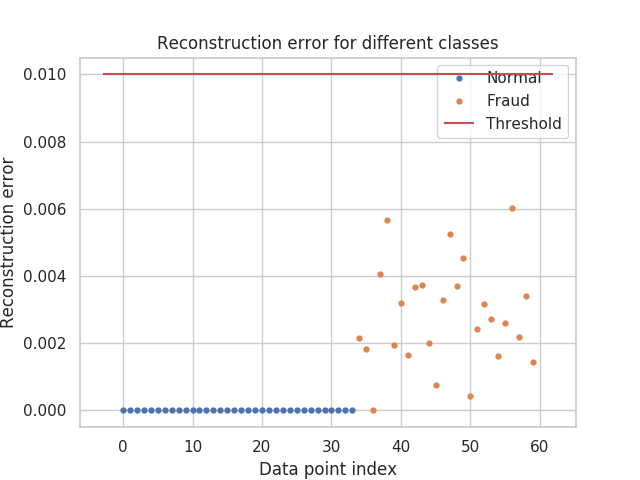
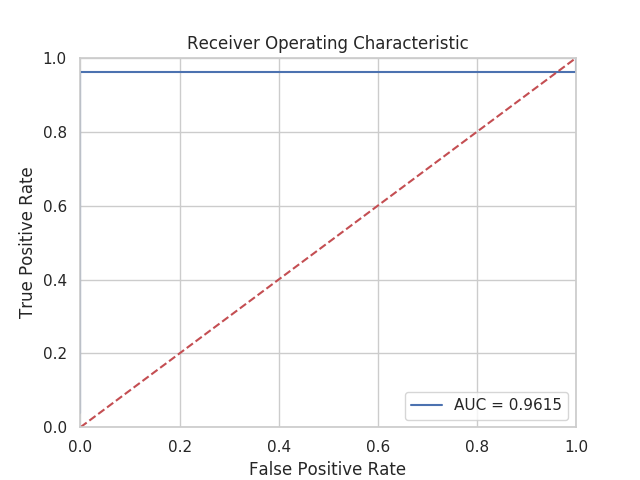
As expected such model gives positive results. A figure plots ROC curve with AUC of 96,15 %:
References
[1] Baker, C. L., Saxe, R., & Tenenbaum, J. B. (2009). Action understanding as inverse planning. Cognition, 113(3), 329-349. DOI
[2] Amato, C., & Shani, G. (2010). High-level reinforcement learning in strategy games. In Proceedings of the International Joint Conference on Autonomous Agents and Multiagent Systems, AAMAS (Vol. 1, pp. 75-82). DOI
[3] Brockman, G., Cheung, V., Pettersson, L., Schneider, J., Schulman, J., Tang, J., & Zaremba, W. (2016). OpenAI Gym. arXiv:1606.01540. arXiv
[4] Duan, Y., Chen, X., Houthooft, R., Schulman, J., & Abbeel, P. (2016). Benchmarking Deep Reinforcement Learning for Continuous Control. arXiv:1604.06778. arXiv